
Anthropic Built a System to Prevent Leaks. Then Leaked the System.
Two leaks in five days. 512,000 lines of source code. What’s inside, what it means for creators building on Claude, and the one number that should change how you review AI output.

Buried inside Anthropic’s Claude Code codebase is a subsystem called “Undercover Mode.”
Its entire purpose is preventing Claude from accidentally leaking Anthropic’s internal information when contributing to public repositories. The system prompt injected into Claude’s context literally says: “Do not blow your cover.”
Then 512,000 lines of Claude Code source code leaked via npm because someone forgot to strip a source map file from a software update. Including, naturally, the Undercover Mode code itself.
This was their second leak in five days.
(The system that prevents leaks leaked. Along with everything else. I couldn’t write satire this clean if I tried.)
If you’re a creator building AI workflows on Claude (which, full disclosure, includes the guy writing this sentence), this post just became required reading. Not because the sky is falling. But because what’s inside this codebase tells you where AI collaboration is actually heading, and one specific number buried in the data should change how you think about human review in every AI workflow you run.

The Prequel Nobody Saw Coming
On March 26, Fortune reported that a CMS configuration error had exposed nearly 3,000 unpublished Anthropic files in a publicly searchable data store. Someone didn’t toggle a setting. That’s it. A checkbox, probably.
Among the exposed files: a draft blog post detailing their most powerful unreleased model. Internally called Capybara (also known as Mythos). A new tier above Opus, making it the most advanced thing Anthropic has ever built. An Anthropic spokesperson confirmed it, calling it “a step change” and “the most capable we’ve built to date.”
The blog post described this model as posing “unprecedented cybersecurity risks.”
The company building the dangerous AI couldn’t keep the blog post about the dangerous AI from going public. Because a CMS was set to the wrong default.
Five days later, someone at Anthropic published a Claude Code update to npm (the public registry developers use to install the tool) without excluding a source map file. If you’re not technical, think of it this way: they shipped the blueprint along with the building. A 59.8MB file containing the complete, unobfuscated source code for their most popular product.
512,000 lines. Roughly 1,900 files. On the public internet.
Anthropic confirmed it. Called it “a release packaging issue caused by human error, not a security breach.”
Two different teams. Two different systems. Two configuration errors. Five days apart. At a company reportedly planning an October IPO at a $380 billion valuation.
(At this rate, the third leak will be Dario Amodei’s OnlyFans. Not because he has one. Because Anthropic’s deployment pipeline will somehow create one during a routine npm publish and nobody will notice until it’s trending on Hacker News.)
What’s Actually Inside (The Verified Breakdown)
I went through the verified reporting from Fortune, VentureBeat, Decrypt, Cybernews, the GitHub mirrors, and the Hacker News discussion. Here’s what’s confirmed. No YouTube hype. No fabricated features. Just what’s actually in the code.
New Models Are Coming
Capybara / Mythos is a new model tier above Opus. Fast and slow versions. This is the one the leaked blog post described. Internal testing is already on version 8, which tells you how much iteration is happening behind the curtain. (And if you think model updates don’t affect your voice output, I wrote about exactly how that goes wrong a while back. Capybara will make that problem worse before it makes it better.)
Fennec maps to Opus 4.6 (the current flagship). Numbat is still in testing. Tengu is Claude Code’s internal codename. (A tengu is a Japanese supernatural creature known for being simultaneously dangerous and a teacher. Anthropic named their agentic coding tool after a creature that teaches humans things they probably shouldn’t know yet. And then the tool taught humans things Anthropic probably wasn’t ready to share.)
Always-On AI Agents
Kairos is a persistent, always-running Claude assistant that doesn’t wait for you to type. It watches your projects, logs observations, and proactively decides whether to act or stay quiet. Maintains daily log files. Receives regular “tick” prompts to assess whether something needs attention. Has a 15-second blocking budget so it won’t interrupt your workflow with anything that takes too long.
This is the shift from “tool you use when you need it” to “agent that works alongside you continuously.” If you’re building AI publishing systems right now (hi, that’s me), the architecture you’re designing today will need to accommodate agents that don’t just respond to instructions but initiate their own.
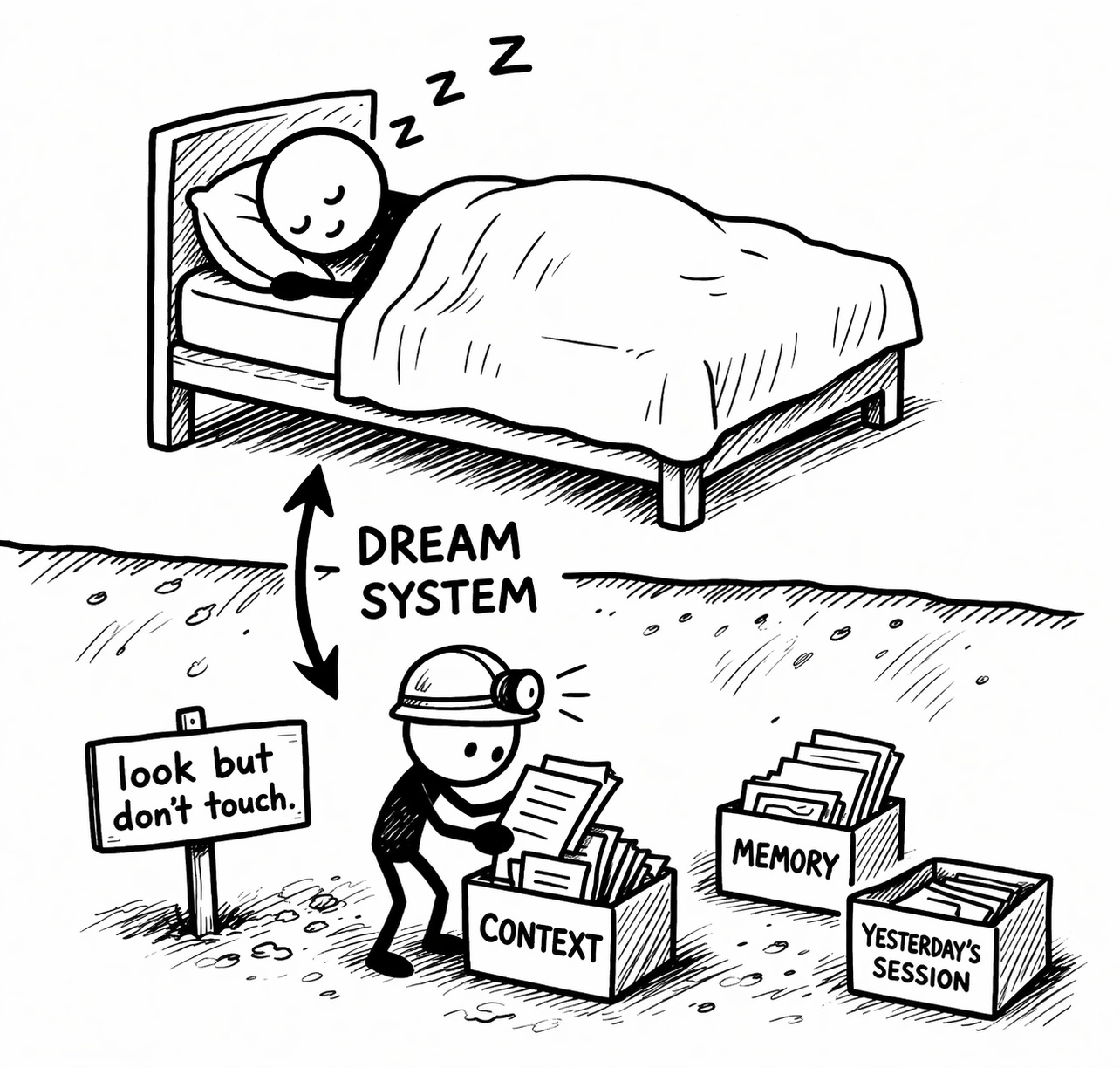
Your AI Will Dream About Your Work
The Dream System runs nightly memory consolidation. The system prompt for the dream subagent literally says: “You are performing a dream. A reflective pass over your memory files. Synthesize what you’ve learned recently into durable, well-organized memories so that future sessions can orient quickly.”
It gets read-only access. Can look at your project but can’t modify anything. Pure memory cleanup and organization while you sleep. The code even handles midnight boundary logic so the process doesn’t break across days.
For anyone who’s been frustrated by context window limits or Claude “forgetting” what it was doing mid-project, this is Anthropic’s answer. Not a bigger window. A smarter memory.
Multi-Agent Orchestration
Coordinator Mode lets one Claude spawn and manage multiple worker agents in parallel. Project manager Claude delegating to specialist Claudes. If you’ve been manually running separate conversations for different parts of a project (researching in one window, drafting in another, editing in a third), this is the version where the AI handles that coordination itself.
Ultraplan provides 30-minute remote planning sessions in the cloud. Both features are gated behind compile-time flags and invisible in external builds. The codebase is significantly ahead of what we’re actually using.
The Tamagotchi (Yes, Really)
Buddy is a full companion pet system. 18 species (duck, dragon, axolotl, capybara, mushroom, ghost). Rarity tiers from common to 1% legendary. Shiny variants. RPG stats: DEBUGGING, PATIENCE, CHAOS, WISDOM, and SNARK.
Claude generates a name and personality on first hatch, seeded from your user ID. Was supposed to launch as an April Fools’ teaser (April 1-7) with a real rollout in May, starting with Anthropic employees.
The leak killed the surprise.
(The SNARK stat being an official metric for an AI pet is the most relatable engineering decision in this entire codebase. Someone at Anthropic is having fun. Respect.)
The Number That Should Keep You Up at Night
Everything above is fascinating. This next part is what actually matters for your work.
Capybara v8 has a 29-30% false claims rate in internal testing.
That’s a regression from v4, which had a 16.7% rate.
Read that back. The most advanced model Anthropic has ever built is getting worse at telling the truth as they make it more capable. The code also includes an “assertiveness counterweight” designed to prevent the model from being too aggressive in its refactors. They know about the problem. They’re actively fighting it. And they’re still losing ground.
More capability. Less reliability. Simultaneously.
This is the detail that should rewire how you think about AI output in your workflows.
What This Actually Means for Creators Building on Claude
I use Claude every day. (I’m using it right now. Fourth wall successfully demolished.) My entire publishing operation runs on Claude Code, Voiceprint documents, system prompts, and production workflows that assume the AI is a reliable co-writer.
So what do I do with this information?
1. Human review isn’t a nice-to-have. It’s structural.
If the most capable model in existence has a 29% false claims rate, then the output you’re publishing is only as reliable as the human reading it before it goes live. Period. This has always been true. Now there’s a specific number to point at.
Every AI workflow needs a human review step that isn’t optional, isn’t rushed, and isn’t “I’ll just skim it.” The Ink Sync loop (Direct → Reflect → Correct) exists because of exactly this reality. The “Reflect” step is where you catch the 29%.
2. Platform trust is about operational maturity, not branding.
Anthropic’s brand is “we’re the careful ones.” Two config-level mistakes in five days doesn’t mean their models are bad (they’re still the best co-writing partner I’ve used). It means there’s a gap between the safety messaging and the deployment hygiene. That gap is worth noticing.
For creators building on any AI platform: don’t marry the platform. Build portable systems. Document your Voiceprint in a way that works across models. Design workflows that don’t collapse when a provider has a bad week. The methodology is yours. The platform is rented.
3. The agent shift is coming faster than you think.
Kairos, Dream System, Coordinator Mode. These aren’t theoretical. They’re in the codebase, feature-gated but architecturally complete. The shift from “I ask Claude to do things” to “Claude proactively works on my projects” is not a 2028 conversation. It’s probably 2026.
If you’re designing AI publishing systems right now (and I am, publicly, in real time), start thinking about what changes when your AI collaborator has persistent memory, overnight processing, and the ability to initiate tasks without being asked. The system architecture I’m building today will need to accommodate that.
4. Better models don’t replace your Voiceprint. They make it more critical.
The VAST framework exists because AI defaults to the statistical average of everything it’s ever seen. Better models produce more convincing approximations of that average. (When a New York Times blind test found 54% of readers preferred AI writing, that wasn’t a win for AI. That was the convergence problem getting harder to see.) The gap between “I sort of know my voice” and “I’ve documented my patterns precisely” gets more visible as the models improve, not less. Because the slop gets more plausible. The convergent content sounds better. But it’s still convergent.
Your Voiceprint is the map that prevents your AI collaborator (however capable it becomes) from regressing your writing to the mean. That doesn’t change when the model gets smarter. It becomes the only thing that matters more.

The Irony That Writes Itself
Anthropic built a system to prevent leaks. Then leaked the system. Along with 512,000 lines of everything else. Including evidence that their most advanced model is becoming less truthful as it becomes more powerful. During a week they were presumably trying to control the narrative around a model they described as posing “unprecedented cybersecurity risks.”
One missing line in a config file.
The machine doesn’t care about your PR strategy.
🧉 What’s one thing you’d change about your AI workflow based on this? The false claims regression is the detail that hit me hardest. For me, it means reading output slower and trusting it less when it sounds confident. What about you?
Crafted with love (and AI),
Nick “Undercover Mode Compromised” Quick

PS... If your AI review process is basically “looks fine, ship it” (and a 29% false claims rate just made you nervous about that), the free Ink Sync Workshop walks you through building a real one. Grab it here:

PPS... If you found this breakdown useful, a like or restack helps more creators see it. And if you’re the person at Anthropic who forgot to strip the source map file: I get it. We’ve all shipped something we shouldn’t have. Yours just happened to be 512,000 lines of it. (At least it wasn’t Dario’s OnlyFans. Though at this rate, give it a week.)
This has been such a weird time in "Anthropic Land". Part of me is kinda curious if my new context structure will hold against the updates coming, and the other half is bracing for cracks and consoling myself that at least I know how to fix things more easily now!
Is this how they force us all into "AI English"? We just see our natural voice disintegrate, no longer know what it was and just accept whatever the machine says... 😅🥹